

Framework DeLM - Botsitting & Botshitting - Google « Faithful Uncertainty » - Tokenmaxxing - Jeff Bezos in space - Pause datacenters...
NL°22 - Moratoires datacenters; Supervision d'agents; LLM d'OVHcloud; Boom financier de SpaceX; DataCalog avec IA au Leclerc; Anthropic domine OpenAI; Emancipation de Microsoft; Genie Ontology...

Actualités IA & Data
L’opposition croissante aux infrastructures physiques de l’IA
L’expansion des infrastructures d’IA, totalisant 1416 centres de données actifs ou en construction aux États-Unis en 2025, cristallise une opposition majeure. Environ 70% des résidents américains rejettent désormais ces implantations locales, motivant l’adoption de 86 moratoires dans 35 États. Ces actifs industriels saturent les ressources : la consommation annuelle projetée atteint 664 milliards de litres d’eau d’ici 2030. En Europe, l’Aragon et l’Attique subissent cette pression en zone de stress hydrique permanent. « L’expansion sans cesse plus importante des technologies d’IA nécessite des infrastructures de plus en plus nombreuses », mais la volatilité des prix de l’électricité (+267% localement) impose des cadres restrictifs. Le Cloud and AI Development Act conditionne désormais les permis de construire à des critères stricts d’efficience énergétique et de gestion hydrique. Cette fronde sociale constitue une variable de risque réglementaire que les hyperscalers ne peuvent plus ignorer dans leurs projections de croissance.
Lire l’article - La fronde contre la prolifération des data centers IA passe un cap aux États-Unis et en Europe

La Charte d’engagement des Data Voices, co-réalisée avec Secrets de Data, est l’aboutissement d’un travail collectif sur l’avenir de la donnée et de l’IA à horizon 2030. Elle repose sur une démarche d’enquête mixte, combinant approche quantitative et qualitative, menée par Huwise auprès d’une centaine de leaders data & IA issus de grandes organisations de dimension internationale, tous secteurs d’activité confondus. Télécharger.
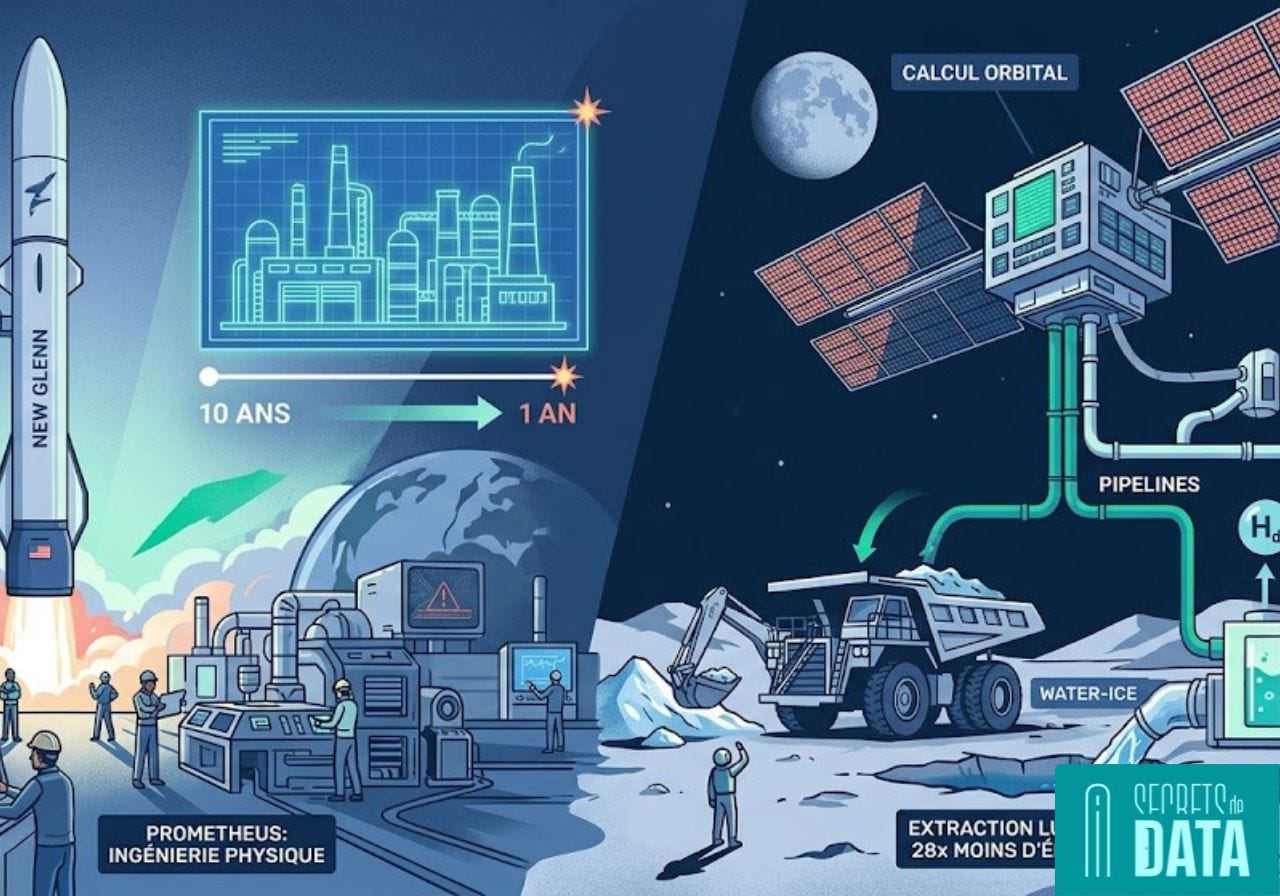
L’expansion industrielle vers l’ingénierie physique et orbitale
Jeff Bezos segmente ses activités via Blue Origin et Prometheus pour externaliser les charges numériques hors de l’atmosphère. Cette stratégie capitalise sur un avantage mécanique : l’extraction de matériaux depuis la Lune requiert 28 fois moins d’énergie que sur Terre. Le computing orbital, alimenté par énergie solaire, vise à absorber l’explosion des besoins de calcul sans saturer les ressources terrestres. Prometheus se distingue des modèles de langage classiques en se focalisant sur des données d’ingénierie physique pour accélérer les cycles de R&D industriels. L’objectif est de réduire les programmes complexes de dix ans à une seule année. Malgré des incidents techniques sur le lanceur New Glenn, la feuille de route vers une infrastructure permanente exploitant l’eau glacée lunaire par électrolyse demeure la priorité opérationnelle du groupe. Bezos anticipe une pénurie de main-d’œuvre qualifiée pour résoudre les problèmes complexes identifiés par ces nouveaux systèmes. Cette transition orbitale actée par les leaders du secteur redéfinit la géopolitique des ressources informatiques mondiales.
Lire l’article - VivaTech 2026 : entre infrastructures orbitales et IA physique, la folle trajectoire industrielle de Jeff Bezos
Industrialisation de l’IA au sein de l’État français
Le gouvernement français déploie « l’Assistant », une interface d’IA générative architecturée avec Mistral AI, auprès d’un million d’agents publics. Cette industrialisation vise à limiter le recours aux solutions non souveraines, déjà pratiqué par 56% des agents testeurs. L’expérimentation sur 10 000 agents a validé des gains de productivité de 12% sur la rédaction et 16% sur la synthèse documentaire. L’infrastructure repose sur une logique « multiprise » permettant de substituer les modèles selon les impératifs de sécurité ou les risques politiques. Le coût de ce déploiement est estimé à 750 000 euros, absorbé sans surcoût budgétaire. L’État prévoit également l’intégration de modèles spécialisés, comme DiploIA pour la traduction et Aria pour le réseau France Services, afin de couvrir des besoins métiers critiques. Cette réorganisation inclut la réinternalisation des compétences numériques à partir de 2027 pour réduire la dépendance aux prestations externes. L’objectif final est de construire une méthode commune pour anticiper les effets de l’IA sur l’organisation du travail public.
Lire l’article - “L’IA dans l’Etat” : avec son assistant IA généralisé à plus d’un million d’agents, le gouvernement français veut reprendre la main sur ses usages
Stratégie de développement de LLM propriétaires par OVHcloud
Octave Klaba acte le pivot stratégique d’OVHcloud vers le développement de « frontier models » propriétaires pour sécuriser l’autonomie du groupe face à la volatilité des fournisseurs américains. Ce virage s’appuie sur l’acquisition de Dragon LLM pour structurer un « AI Lab » interne. Grâce à l’optimisation des architectures et à l’usage de données synthétiques, le coût d’entraînement d’un modèle de pointe est désormais estimé entre 150 et 200 millions d’euros. L’objectif consiste à proposer une famille de modèles spécialisés pour les secteurs financiers et réglementés, pré-entraînés sur le supercalculateur Jupiter. OVHcloud garantit l’absence d’exploitation des données clients et prévoit de basculer ces technologies en open source après avoir atteint des seuils de performance définis. Cette stratégie cible directement la réduction de la latence et l’optimisation des coûts d’inférence pour améliorer la rentabilité des solutions. Le fournisseur roubaisien ambitionne ainsi de maîtriser les briques essentielles de l’IA pour garantir son avenir technologique et commercial.
Lire l’article - OVHcloud annonce le développement de ses propres LLM
Réussir dans l’IA

Supervision des agents : Le modèle du stagiaire enthousiaste
Les experts du secteur comparent désormais les agents IA à des stagiaires malavisés nécessitant une supervision stricte. Contrairement aux API traditionnelles prévisibles, les agents connectent les outils à la volée pour atteindre un objectif, ce qui induit des risques d’exfiltration de données ou d’achats non autorisés. Le spectre d’une « IA fantôme » opérant via des identifiants dotés de permissions excessives impose une redéfinition des protocoles de sécurité. Une supervision humaine approfondie doit valider l’intention à chaque étape pour limiter les dérives opérationnelles. Les professionnels sont incités à adopter des SDK pour encadrer ces entités non-déterministes avec des instructions précises, assurant une traçabilité complète. Le défi consiste à maintenir l’équilibre entre la créativité nécessaire à la productivité et l’application de contrôles prévisibles. La visibilité totale et la définition claire de l’intention deviennent les piliers de la gouvernance des agents autonomes. L’absence de limites strictes expose les organisations à des actions imprévisibles sur leurs systèmes critiques.
Lire l’article -Considérez vos agents IA comme des stagiaires enthousiastes mais... des stagiaires quand même !
Gestion de l’incertitude et réduction des hallucinations
Google Research introduit la « faithful uncertainty » pour aligner les réponses linguistiques des LLM sur leur confiance statistique interne. Ce mécanisme de métacognition permet au modèle d’émettre des hypothèses nuancées plutôt que de basculer dans un binaire « réponse ou abstention ». L’enjeu est de réduire la « taxe d’utilité » : imposer un taux d’erreur de 5% force actuellement les modèles à rejeter 52% de leurs réponses correctes. En signalant explicitement son doute, l’agent préserve la confiance de l’utilisateur tout en optimisant l’usage des outils externes. Cette couche de contrôle interne permet de déclencher des recherches API uniquement lorsque le score de confiance est insuffisant. La distinction entre savoir des faits et savoir ce qui est connu devient le fondement de la fiabilité agentique. Cette approche transforme les hallucinations en « erreurs qualifiées », évitant le sycophentisme face à des sources externes contradictoires. La mise en œuvre de cette capacité nécessite cependant un réglage fin via l’apprentissage par renforcement pour éviter le mimétisme de l’incertitude.
Lire l’article - Google researchers introduce ‘faithful uncertainty,’ allowing LLMs to offer best guesses instead of hallucinations
Décentralisation et réduction des coûts via DeLM
Le framework DeLM de Stanford remet en question la nécessité d’un orchestrateur central, souvent identifié comme un goulot d’étranglement. Dans cette architecture, les agents collaborent via une base de connaissances partagée composée de « gists » ou résumés d’informations vérifiées. Les agents partagent leurs échecs et leurs progrès, évitant ainsi la redondance des explorations coûteuses. Sur le benchmark SWE-bench, DeLM surpasse les approches centralisées de 10,5% tout en réduisant les coûts de traitement de 50%. Le mécanisme d’« unfolding » permet aux agents d’accéder aux détails bruts uniquement si leur tâche spécifique le requiert, optimisant la fenêtre de contexte. Cette décentralisation améliore la robustesse globale en transformant les contraintes vérifiées en états partagés contraignants. DeLM démontre que la coordination directe entre agents est non seulement possible, mais plus performante pour le raisonnement sur documents longs. La réduction de la latence de coordination constitue un avantage compétitif majeur pour les architectures multi-agents complexes.
Lire l’article - Stanford’s DeLM cuts multi-agent task costs 50% — without a central orchestrator
Optimisation du catalogue de données chez Leclerc via Gemini
Leclerc a fait évoluer son architecture de gestion de catalogue vers un agent autonome basé sur Google ADK. Après avoir testé une approche managée sur Vertex AI puis un système RAG sur LangChain, l’organisation a opté pour un agent capable de raisonner pour sélectionner dynamiquement ses outils (BigQuery, lexiques métiers, Confluence). L’agent ne se limite plus à l’extraction ; il suggère des requêtes SQL et estime le coût de leur exécution. Actuellement en production pour 150 utilisateurs, le système traite 1000 questions mensuelles pour un coût d’infrastructure inférieur à 300 euros par mois. L’architecture permet de générer à la volée des diagrammes de relations entre les tables de données. L’évolution du projet cible des protocoles de communication Agent-to-Agent (A2A) pour structurer une plateforme multi-agent globale d’ici 2027. Cette mutation technologique démontre la viabilité des agents de raisonnement pour rationaliser des patrimoines de données hétérogènes. La rapidité de mise en production via Google ADK confirme la maturité des frameworks agentiques actuels.
Lire l’article - Leclerc gère son data catalog avec un agent IA
Le modèle Sillon de la RATP : Détection critique et souveraineté
La RATP déploie « Sillon », un modèle de raisonnement de 600 millions de paramètres conçu avec Pleias pour qualifier les messages d’urgence. Contrairement aux modèles Mistral initialement utilisés, Sillon offre une transparence totale sur ses données d’entraînement, excluant les biais éthiques et environnementaux. Le modèle a été entraîné sur le supercalculateur Jean-Zay à l’aide de 1,7 million de données synthétiques pour protéger les informations personnelles des voyageurs. Sillon génère des traces de raisonnement en plusieurs étapes avant d’émettre une classification binaire de criticité. Déployé sur l’infrastructure souveraine de Scaleway, il permet aux superviseurs de réagir plus précocement lors d’incidents, tout en maintenant un contrôle humain final. L’établissement public privilégie ici la sobriété et la maîtrise de la base de pré-entraînement française. Cette approche permet de qualifier jusqu’à 1000 messages par heure lors de crises majeures sur le réseau. Le groupe prévoit de publier une version open source de ce modèle de raisonnement spécialisé pour le secteur des transports.
Lire l’article - Avec son modèle d’IA Sillon, la RATP veut aider ses agents à mieux détecter les messages d’urgence adressés à son réseau
Les chiffres de l’IA

Financement de l’autonomie stratégique face aux restrictions d’accès
La suspension par Anthropic de l’accès aux modèles Claude Fable et Mythos pour les utilisateurs non américains, sous injonction de la Maison Blanche, concrétise le risque de « kill switch ». En réaction, le gouvernement français débloque 655 millions d’euros via France 2030 pour soutenir les infrastructures et la recherche nationale. Cette enveloppe vise à réduire la dépendance technologique en favorisant des champions locaux comme ChapsVision, sélectionné par la DGSI au détriment de Palantir pour le projet Argonos. Le Conseil de l’IA et du numérique souligne que l’accès aux modèles est désormais un enjeu de sécurité nationale aussi critique que l’hébergement cloud. Ce montant reste toutefois modeste face aux 500 milliards de dollars projetés par Stargate aux États-Unis. La France assume désormais la nécessité de ne pas dépendre du bon vouloir de partenaires étrangers pour ses fonctions régaliennes. L’épisode Anthropic marque une rupture dans la perception de l’IA, transformant l’accès aux poids des modèles en un levier de puissance géopolitique immédiat.
Le paradoxe de la productivité : Botsitting et Botshitting
Le Work AI Institute documente une perte de 6,4 heures par semaine en « botsitting », soit le travail humain nécessaire pour contextualiser et vérifier les productions de l’IA. Ce phénomène engendre le « botshitting », où 69% des utilisateurs livrent des résultats non vérifiés par manque de temps. Plus critique, 41% admettent livrer des travaux qu’ils ne sauraient expliquer, déléguant leur jugement professionnel à la machine. Ce paradoxe neutralise une large part des gains de productivité, seuls 13% des employés constatant une amélioration réelle des performances de l’entreprise. La surcharge liée au débogage devient une source majeure d’épuisement professionnel. Les organisations les plus matures valorisent désormais la compétence de savoir quand ne pas utiliser l’IA pour préserver la qualité décisionnelle. L’utilisation d’outils non homologués par 54% des travailleurs performants souligne un défaut de gouvernance interne. La réussite de l’intégration de l’IA dépend de la capacité des dirigeants à valoriser le travail de supervision humaine.
Lire l’article - Les humains perdent 6,4 heures par semaine à surveiller l’IA
La soutenabilité financière face au « tokenmaxxing »
Le phénomène de « tokenmaxxing », incitant à une utilisation intensive de l’IA sans objectif de valeur, génère des factures de jetons insoutenables. Le coût réel de l’IA reste opaque car il dépend de variables indéterminées : le volume de tokens par requête et le nombre d’itérations nécessaires à l’exactitude. Ce manque de prévisibilité budgétaire menace la rentabilité à long terme et pousse les entreprises vers des modèles de paiement à l’usage restrictifs. L’impossibilité de budgétiser précisément les dépenses pourrait tarir prématurément le pipeline de revenus vers OpenAI ou Anthropic. Les organisations commencent à exiger que l’usage de l’IA serve des objectifs métiers mesurables plutôt que des leaderboards de consommation. Si les gains de productivité ne compensent pas les coûts opérationnels, le modèle économique des hyperscalers risque une contraction brutale. La volatilité des tarifs par token ajoute une couche d’incertitude pour les directions financières. La survie des services dépendra de leur capacité à démontrer un ROI tangible au-delà de l’effet d’annonce.
Lire l’article - Drilling Into AI’s Financial Sustainability
L’hégémonie financière et technologique de SpaceX
SpaceX a finalisé une introduction en bourse historique, levant 85,7 milliards de dollars au Nasdaq. Cette capitalisation massive installe l’entreprise devant Amazon et fait d’Elon Musk le premier trillionnaire mondial. Cette réserve de capital permet de consolider Starlink comme pivot mondial du Edge Computing et des infrastructures cloud décentralisées. Le marché potentiel est estimé à 28 500 milliards de dollars, incluant la connectivité pour les sites industriels isolés et les services de secours. Tandis que le projet Kuiper d’Amazon accuse des retards réglementaires, SpaceX revendique plus de 80% de la masse mise en orbite mondialement depuis trois ans. La valorisation franchit le cap des 2 790 milliards de dollars, malgré un ratio cours/chiffre d’affaires élevé de 112. Cette hégémonie spatiale exerce une pression directe sur les opérateurs télécoms et cloud traditionnels. SpaceX s’impose comme l’infrastructure critique par excellence pour le désenclavement numérique global.
Lire l’article - L’introduction en bourse de SpaceX atteint 85,7 milliards de dollars
Le basculement du marché des abonnements entreprise vers Anthropic
Anthropic dépasse OpenAI sur le segment des abonnements entreprise, atteignant 41% de parts de marché. Ce basculement est corrélé aux restrictions imposées par Washington sur les modèles Fable 5 et Mythos 5 pour motifs de sécurité nationale. La désignation d’Anthropic comme risque pour la chaîne d’approvisionnement par le Département de la Défense a généré un « effet de halo », renforçant sa perception de puissance technologique. Mythos 5 s’impose comme la référence pour les institutions certifiées exigeant des capacités de pointe sans limitations de performances. Tandis qu’OpenAI domine le marché grand public, Anthropic capitalise sur une image de robustesse et de conformité stratégique. Cette progression de 2,5 points en un mois souligne l’importance des garanties de sécurité dans les arbitrages des CDO. L’interdiction réglementaire paradoxalement valide la supériorité technique perçue de ses modèles. Le rapport de force évolue au profit d’acteurs identifiés comme critiques pour la souveraineté américaine.
Lire l’article - Anthropic dépasse OpenAI sur le marché des abonnements IA en entreprise
Voix de l’IA

L’émancipation de Microsoft vis-à-vis d’OpenAI
Microsoft s’affranchit des clauses restrictives de son contrat avec OpenAI pour poursuivre de manière autonome la « superintelligence » via sa division MAI. L’entreprise déploie la famille de modèles MAI, entraînée à partir de zéro sur des données licenciées sans distillation de modèles tiers. Microsoft introduit la métrique « Actions Quotient » (AQ), privilégiant la capacité d’action autonome dans les flux logiciels plutôt que la simple conversation. Cette stratégie s’appuie sur le processeur Maia 200, 30% plus efficace que les solutions Nvidia pour ses charges de travail. L’agent Microsoft Scout, basé sur OpenClaw, illustre ce passage de l’intelligence pure à l’exécution automatisée. En contrôlant l’intégralité de la stack, du silicium aux modèles, Microsoft réduit sa dépendance stratégique tout en optimisant ses coûts d’exploitation. L’entreprise capitalise sur sa présence historique dans les flux de travail du Fortune 500 pour entraîner ses agents sur des données métiers exclusives. Cette verticalisation marque une étape majeure vers l’autosuffisance technologique de la firme de Redmond.
Lire l’article - Microsoft AI chief says company was “set free” from OpenAI to pursue superintelligence
Gouvernance et ontologie automatisée chez Databricks
Databricks déploie Genie Ontology, un système d’indexation automatisé qui cartographie les connaissances de l’entreprise via l’algorithme OntoRank. Ce système résout les conflits de données et réduit la latence en limitant le volume d’informations explorées par les agents. Intégré à Unity Catalog, Genie Ontology hérite des permissions de sécurité et prévient les boucles agentiques infinies, dont le coût peut atteindre six chiffres en un weekend. Contrairement aux ontologies manuelles, ce système permet aux agents de définir eux-mêmes la couche de données pertinente. Cette approche « zero shot » vise à obtenir la bonne réponse dès la première interaction sans guidage humain. Databricks positionne cette technologie comme le « PageRank » de l’entreprise, indispensable pour ouvrir le contexte métier aux agents IA. La gouvernance dynamique et réactive devient ainsi un moteur de performance plutôt qu’une contrainte. Plus de 14 000 clients utilisent déjà cette couche de gouvernance unifiée pour leurs projets de production.
Lire l’article - Genie One : Databricks lance une ontologie automatisée pour ses agents IA
Optimisation hardware : Le CPU Graviton5 d’AWS
Amazon Web Services déploie le processeur Graviton5, une puce Arm de 192 cœurs conçue pour les charges de travail agentiques massives. Cette architecture réduit la latence de transfert de données de 33% et offre des gains de performance de 35% sur l’inférence machine learning. La sécurité est assurée par le Nitro Isolation Engine, garantissant un cloisonnement des workloads par vérification mathématique formelle. Plus de 120 000 clients, dont Meta et Snowflake, adoptent déjà ces infrastructures pour optimiser leur ratio performance/coût. En contrôlant l’ensemble de la chaîne de production, du silicium au cloud, AWS s’affranchit des solutions GPU génériques coûteuses. Le Graviton5 supporte la mémoire DDR5-8800 et l’interface PCIe Gen 6 pour maximiser la bande passante. Cette stratégie de verticalisation permet à AWS de proposer des instances EC2 M9g optimisées pour l’orchestration multi-étapes. Le CPU se repositionne ainsi au centre de la compétition pour l’infrastructure IA grâce à son efficience énergétique.
Lire l’article - Graviton5 : AWS déploie son processeur maison pour l’ère des agents IA
L’avènement du code agentique : Le rachat de Cursor par SpaceX
SpaceX orchestre l’acquisition d’Anysphere, éditeur de l’IDE Cursor, pour 60 milliards de dollars après le retrait stratégique de Microsoft. L’objectif est d’intégrer nativement la programmation agentique au sein de xAI en s’appuyant sur le cluster Colossus, doté de puces Nvidia H100. Cette opération porte un coup direct à GitHub Copilot en transformant le développement logiciel en un processus piloté de bout en bout par l’IA. Contrairement aux assistants de suggestion classiques, Cursor pilotera la création et le déploiement d’applications complexes via ses modèles « Composer ». La puissance de calcul massive de Colossus constitue une barrière à l’entrée majeure pour les concurrents. SpaceX se positionne ainsi pour automatiser intégralement les cycles de livraison logicielle au profit de xAI, valorisée à 1 250 milliards de dollars. Ce rachat acte l’obsolescence programmée du codage manuel dans les structures industrielles de pointe. L’intégration verticale totale permet à Musk de contrôler la production logicielle comme un actif stratégique de premier plan.
Lire l’article - SpaceX s’empare de Cursor pour 60 milliards de dollars : le jour où le code est devenu agentique